
ApexSQL Backup is a tool for Microsoft SQL Server, intended for database backup and restore job management. The application supports all native SQL Server backups (full, differential and transaction log backups), and allows users to easily create, save and manage all backup related jobs. ApexSQL Backup can be used to run, schedule and monitor all backup operations across the domain from a single location.

SQL SERVER – Database Disaster Recovery Process
Many SQL Server DBAs are from time to time confronted with a disaster caused by unintentional or malicious changes on their database. Whatever the nature or intention of these changes are, they can cause great issues whether it was the data loss or a structure loss. With this in mind, it is important to start with the recovery process as soon as possible. Having a recovery scenario and solution for these situations prepared is also a great benefit, and is generally advised where possible. Whatever enhances our chance to recover in case of a disaster, and increases chances of successful and full recovery should be taken without any second thoughts. In this blog post we will learn about Database Disaster Recovery Process.

SQL SERVER – How to Recover Truncated or Deleted Data When a Database Backup is or is not Available
Recovering lost data that was deleted or truncated can be fairly quick and easy, depending on the environment in which the database resides, recovery measures implemented before and after the data loss has occurred, and the tools used for the job. In this blog post we will learn about how to recover truncated or deleted data when a database is (or not) available.
SQL SERVER – Tracking Database Dependencies
If database changes are needed to be made at a column level, it’s essential that you perform impact assessment in order to determine which objects will be affected after the change. This means that SQL table column dependencies within a database need to be analyzed.
ApexSQL Clean is a tool that is used to analyze SQL server database dependencies and also to remove unwanted objects.
To analyze table column dependencies within a SQL database the first thing you need to do is to create a new project. That can be done by clicking the New button in the Home tab and choosing the desired server and the database.
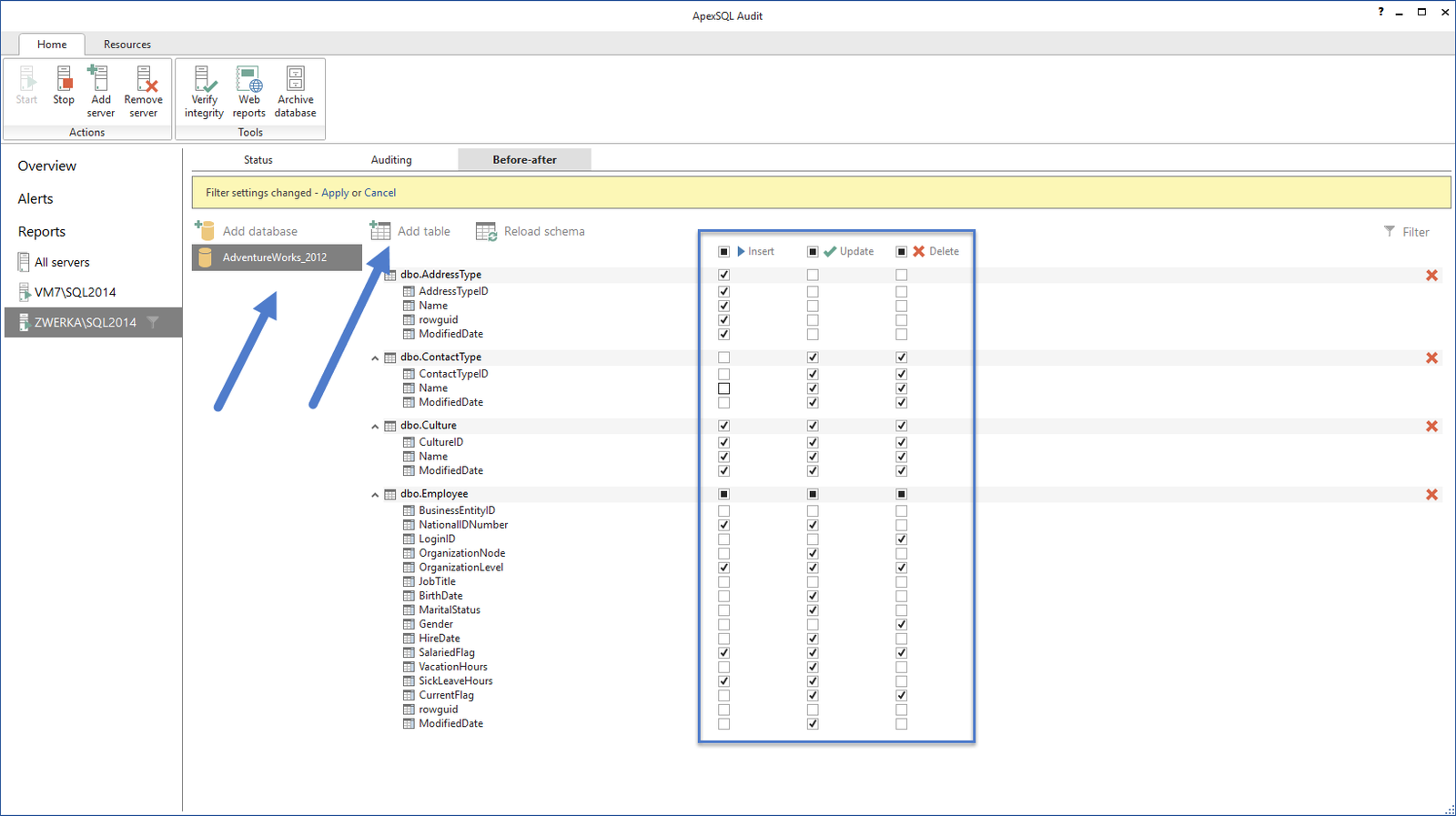
SQL SERVER – Database Auditing and Compliance
ApexSQL Audit is a tool which is used to audit SQL Server events for the purpose of general auditing as well as to meet strict SQL Server compliance standards. ApexSQL Audit can be used to audit more than 170 SQL Server events, including DDL and DML operations, SQL Server logins, security events, query execution… ApexSQL Audit can be used by DBA to meet complex database auditing requirements as well as several compliance standards, including HIPAA, SOX, PCI, FISMA, FERPA, FDA and more.

SQL SERVER – Create Database and BI (SSAS, SSRS, SSIS) Documentation
ApexSQL Doc is a simple but powerful tool which is used for documenting SQL Server databases, SSIS packages, SSAS cubes and SSRS items. It enables users to customize the documentation by including/excluding needed database objects and settings and to generate the documentation in various output formats like, CHM, HTML, PDF and Word formats. Let us learn about how to create BI (SSAS, SSRS, SSIS) documentation.
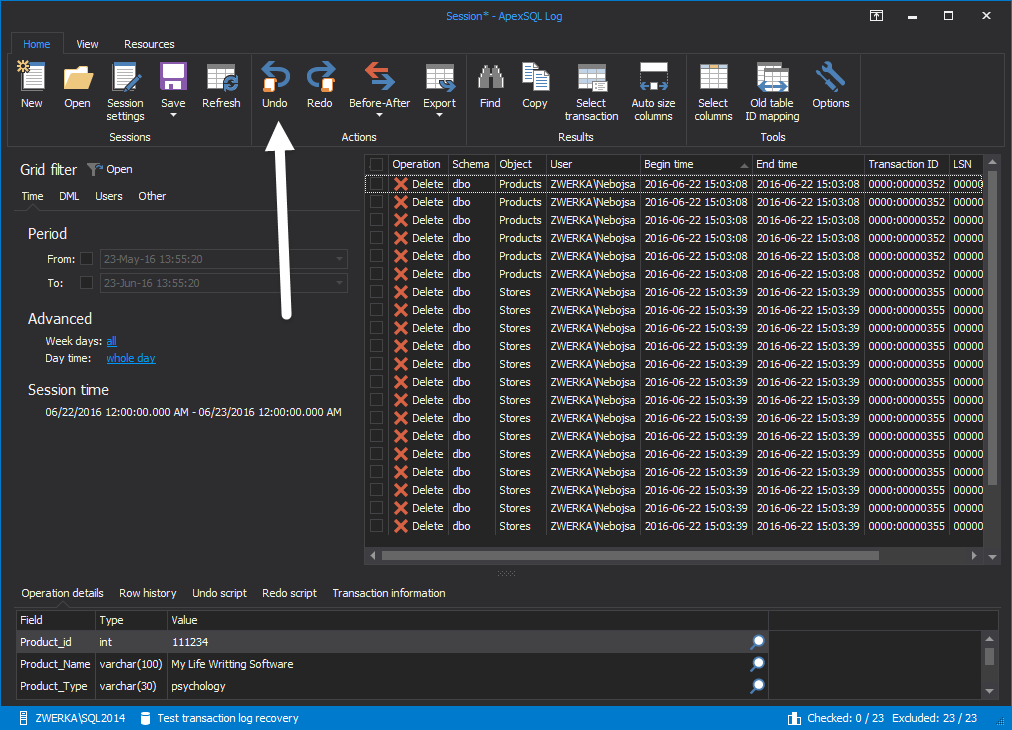
Recover Lost Data Using the Transaction Log Files
Every now and then, experienced SQL Server DBAs as well as the SQL Server rookies find themselves in the unpleasant situation when some important data has been changed or lost with the monumental task to solve this in the most efficient way. Regardless of the change source – was it an internal or external user, the intent behind it – unintended mistake or a malicious change, or even the exact nature of the change – update, delete, drop or something else, database administrators are faced with the task to recover the lost data and enable users to continue using the database as if the recovery was never required by providing the data recovery. Let us learn about how to recover lost data using the transaction log files.