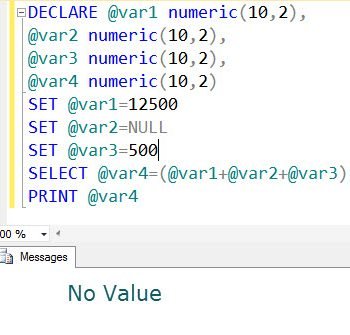
This is a follow-up blog post to my earlier blog post written about SQL SERVER – Writing Your First Subquery From a Single Table. In the blog post, we discuss how to write a correlated subquery and why it is actually necessary. In a query, a correlated subquery is a subquery that uses values from the outer query. Subqueries are usually running once for each row processed for outer query and that is why they are often inefficient as well.

Here is a sample query which is based on WideWorldImporters. In this query, we are trying to find out the StockItemID and QuantityOnHand where we have LastCostPrice of the item more than the average cost of the total sales UnitPrice.
SELECT [StockItemID],[QuantityOnHand], [LastCostPrice] FROM [WideWorldImporters].[Warehouse].[StockItemHoldings] sih WHERE sih.LastCostPrice > (SELECT AVG(ol.UnitPrice) FROM [WideWorldImporters].[Sales].[OrderLines] ol WHERE sih.StockItemID = ol.StockItemID)
In the above query you can see that we are running a subquery on the OrderLines for every single StockItemId we are finding from StockItemHoldings table. As you can see the subquery can’t be run independently, it is a correlated subquery.
Additionally, another great example you can often find on the internet is to find out all the employee where their salary is above average for the employees in their department.
Here is the query which is due to curtsey of Wikipedia:
SELECT employee_number, name FROM employees emp WHERE salary > ( SELECT AVG(salary) FROM employees WHERE department = emp.department);
Reference: Pinal Dave (https://blog.sqlauthority.com)