
We will go over how to optimize Stored Procedure with making simple changes in the code. Please note there are many more other tips, which we will cover in future articles.

- Include SET NOCOUNT ON statement: With every SELECT and DML statement, the SQL server returns a message that indicates the number of affected rows by that statement. This information is mostly helpful in debugging the code, but it is useless after that. By setting SET NOCOUNT ON, we can disable the feature of returning this extra information. For stored procedures that contain several statements or contain Transact-SQL loops, setting SET NOCOUNT to ON can provide a significant performance boost because network traffic is greatly reduced.
CREATE PROC dbo.ProcName AS SET NOCOUNT ON; --Procedure code here SELECT column1 FROM dbo.TblTable1 -- Reset SET NOCOUNT to OFF SET NOCOUNT OFF; GO
- Use schema name with object name: The object name is qualified if used with schema name. Schema name should be used with the stored procedure name and with all objects referenced inside the stored procedure. This help in directly finding the complied plan instead of searching the objects in other possible schema before finally deciding to use a cached plan, if available. This process of searching and deciding a schema for an object leads to COMPILE lock on stored procedure and decreases the stored procedure’s performance. Therefore, always refer the objects with qualified name in the stored procedure like
SELECT * FROM dbo.MyTable -- Preferred method -- Instead of SELECT * FROM MyTable -- Avoid this method --And finally call the stored procedure with qualified name like: EXEC dbo.MyProc -- Preferred method --Instead of EXEC MyProc -- Avoid this method
- Do not use the prefix “sp_” in the stored procedure name: If a stored procedure name begins with “SP_,” then SQL server first searches in the master database and then in the current session database. Searching in the master database causes extra overhead and even a wrong result if another stored procedure with the same name is found in master database.
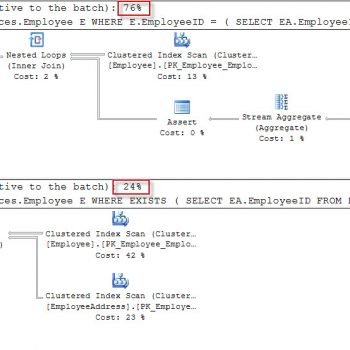
- Use IF EXISTS (SELECT 1) instead of (SELECT *): To check the existence of a record in another table, we uses the IF EXISTS clause. The IF EXISTS clause returns True if any value is returned from an internal statement, either a single value “1” or all columns of a record or complete recordset. The output of the internal statement is not used. Hence, to minimize the data for processing and network transferring, we should use “1” in the SELECT clause of an internal statement, as shown below:
IF EXISTS (SELECT 1 FROM sysobjects WHERE name = 'MyTable' AND type = 'U')
- Use the sp_executesql stored procedure instead of the EXECUTE statement.
The sp_executesql stored procedure supports parameters. So, using the sp_executesql stored procedure instead of the EXECUTE statement improve the re-usability of your code. The execution plan of a dynamic statement can be reused only if each and every character, including case, space, comments and parameter, is same for two statements. For example, if we execute the below batch:
DECLARE @Query VARCHAR(100) DECLARE @Age INT SET @Age = 25 SET @Query = 'SELECT * FROM dbo.tblPerson WHERE Age = ' + CONVERT(VARCHAR(3),@Age) EXEC (@Query)
If we again execute the above batch using different @Age value, then the execution plan for SELECT statement created for @Age =25 would not be reused. However, if we write the above batch as given below,
DECLARE @Query NVARCHAR(100) SET @Query = N'SELECT * FROM dbo.tblPerson WHERE Age = @Age' EXECUTE sp_executesql @Query, N'@Age int', @Age = 25
the compiled plan of this SELECT statement will be reused for different value of @Age parameter. The reuse of the existing complied plan will result in improved performance.
- Try to avoid using SQL Server cursors whenever possible: Cursor uses a lot of resources for overhead processing to maintain current record position in a recordset and this decreases the performance. If we need to process records one-by-one in a loop, then we should use the WHILE clause. Wherever possible, we should replace the cursor-based approach with SET-based approach. Because the SQL Server engine is designed and optimized to perform SET-based operation very fast. Again, please note cursor is also a kind of WHILE Loop.
- Keep the Transaction as short as possible: The length of transaction affects blocking and deadlocking. Exclusive lock is not released until the end of transaction. In higher isolation level, the shared locks are also aged with transaction. Therefore, lengthy transaction means locks for longer time and locks for longer time turns into blocking. In some cases, blocking also converts into deadlocks. So, for faster execution and less blocking, the transaction should be kept as short as possible.
- Use TRY-Catch for error handling: Prior to SQL server 2005 version code for error handling, there was a big portion of actual code because an error check statement was written after every t-sql statement. More code always consumes more resources and time. In SQL Server 2005, a new simple way is introduced for the same purpose. The syntax is as follows:
BEGIN TRY --Your t-sql code goes here END TRY BEGIN CATCH --Your error handling code goes here END CATCH
Reference: Pinal Dave (https://blog.sqlauthority.com)




181 Comments. Leave new
A very useful collection of tips.
Though I would expect a few people to come up with the ‘it depends’ and ‘not always’ arguments, this is certainly a helpful set of tips/best-practices that every TSQL developer should add to his/her check list.
ugh..I have a complex stor proc that I could so use all of your help on. It runs fine but takes over 8 hours to run! Any suggestions would be so greatly appreciated.
BEGIN
— SET NOCOUNT ON added to prevent extra result sets from
— interfering with SELECT statements.
SET NOCOUNT ON;
/*
IF OBJECT_ID(‘tempdb..#tempAgingRecords’) IS NOT NULL
drop table #tempAgingRecords
*/
declare @itemid varchar(40),
@dataareaid varchar(10)
–Master records
select distinct t4.product_number itemid,
t3.company_id dataareaid,
1 processed
into #tempAgingRecords
from edw.dbo.f_inventory_transaction t1
left outer join edw.dbo.dim_inventory_trans_type t2 on
t1.transaction_type_key = t2.transaction_type_key
left outer join edw.dbo.dim_company t3 on
t1.company_key = t3.company_key
left outer join edw.dbo.dim_product t4 on
t1.product_key = t4.product_key
left outer join edw.dbo.dim_date t5 on
t1.date_key = t5.date_key
where –t2.transaction_type not in (‘Profit/Loss’, ‘Transfer’, ‘Quarantine Order’, ‘Transfer Order Shipment’, ‘Transfer Order Receive’)
t2.issues_status in (‘None’, ‘Sold’, ‘Deducted’, ‘Picked’)
and t2.receipt_status in (‘None’, ‘Purchased’, ‘Received’, ‘Registered’)
and t1.transaction_quantity < 0
–and t4.product_number = 'Meiban CM'
and t4.product_key is not null
and t5.[date] ‘1/1/1900’
order by t4.product_number
–Variables for aging process
declare @negTable table (
negDatestatus datetime,
negQty decimal(28,12),
negProcessed int,
negRecid bigint,
negInventoryAmount decimal(28,12)
)
declare @posTable table (
posDatestatus datetime,
posQty decimal(28,12),
posProcessed int,
posRecid bigint,
posInventoryAmount decimal(28,12)
)
declare @negDatestatus datetime,
@negQty decimal(28,12),
@posDatestatus datetime,
@posQty decimal(28,12),
@negRecid bigint,
@posRecid bigint,
@negInventoryAmount decimal(28,12),
@posInventoryAmount decimal(28,12)
truncate table work_invent_trans_aging
while (select sum(processed) from #tempAgingRecords) 0
begin
select @itemid = itemid, @dataareaid = dataareaid from #tempAgingRecords where processed 0
insert into @negTable
select t5.[date] datestatus,
sum(t1.transaction_quantity) qty,
1 processed,
rec_id,
sum(case when t3.company_id = ‘rel’
then isnull(case when issues_status in (‘None’, ‘Sold’, ‘Deducted’,’Picked’)
and receipt_status in (‘None’, ‘Purchased’, ‘Received’, ‘Registered’)
then t1.transaction_quantity * t4.unit_cost end, 0)
else isnull(case when issues_status in (‘None’, ‘Sold’, ‘Deducted’,’Picked’)
and receipt_status in (‘None’, ‘Purchased’, ‘Received’, ‘Registered’)
then t1.posted_cost_amount end, 0) +
isnull(case when issues_status in (‘None’, ‘Sold’, ‘Deducted’,’Picked’)
and receipt_status in (‘None’, ‘Purchased’, ‘Received’, ‘Registered’)
then t1.adjustment_cost_amount end, 0) +
isnull(case when issues_status in (‘Deducted’,’Picked’)
or receipt_status in (‘Received’, ‘Registered’)
then t1.physical_cost_amount end, 0) end) as InventoryAmount
from edw.dbo.f_inventory_transaction t1
left outer join edw.dbo.dim_inventory_trans_type t2 on
t1.transaction_type_key = t2.transaction_type_key
left outer join edw.dbo.dim_company t3 on
t1.company_key = t3.company_key
left outer join edw.dbo.dim_product t4 on
t1.product_key = t4.product_key
left outer join edw.dbo.dim_date t5 on
t1.date_key = t5.date_key
where t4.product_number = @itemid
and t3.company_id = @dataareaid
–and t2.transaction_type not in (‘Profit/Loss’, ‘Transfer’, ‘Quarantine Order’, ‘Transfer Order Shipment’, ‘Transfer Order Receive’)
and t2.issues_status in (‘None’, ‘Sold’, ‘Deducted’, ‘Picked’)
and t2.receipt_status in (‘None’, ‘Purchased’, ‘Received’, ‘Registered’)
and t1.transaction_quantity < 0
–and t4.product_number is not null
and t5.[date] ‘1/1/1900’
group by t5.[date],
rec_id
having sum(t1.transaction_quantity) 0
–and t4.product_number is not null
and t5.[date] ‘1/1/1900’
group by t5.[date],
rec_id
having sum(t1.transaction_quantity) > 0
–Get the first positive quantity
select @posRecid = posRecid, @posDatestatus = posDatestatus, @posQty = posQty, @posInventoryAmount = posInventoryAmount from @posTable p1 where posProcessed 0 order by posDatestatus desc, posRecid desc
while (select isnull(sum(negProcessed), 0) from @negTable n1) 0
begin
–Get negative quantity
select @negRecid = negRecid, @negDatestatus = negDatestatus, @negQty = negQty, @negInventoryAmount = negInventoryAmount from @negTable n2 where negProcessed 0 order by negDatestatus desc, negRecid desc
if (select isnull(sum(posProcessed), 0) from @posTable) = 0
begin
–Insert negative value if there are no positive quantities
insert into work_invent_trans_aging
values (@negRecid, @posRecid, @itemid, @dataareaid, @negDatestatus, ‘1/1/1900’, @negQty, ‘New1’, @negInventoryAmount)
set @negQty = 0
set @negInventoryAmount = 0
end
else
begin
if @posQty > (@negQty * -1)
begin
–Write into result table the consumed negative amount
insert into work_invent_trans_aging
values (@negRecid, @posRecid, @itemid, @dataareaid, @negDatestatus, @posDatestatus, @negQty, ‘Original’, @negInventoryAmount)
set @posQty = @posQty + @negQty
set @posInventoryAmount = @posInventoryAmount + @negInventoryAmount
end
else
–If the negative quantity has left to consume, get another positive record
while @negQty < 0
begin
–If there are no more positive record (still negatives left), then insert and end
if (select isnull(sum(posProcessed), 0) from @posTable) = 0
begin
insert into work_invent_trans_aging
values (@negRecid, @posRecid, @itemid, @dataareaid, @negDatestatus, '1/1/1900', @negQty, 'New2', @negInventoryAmount)
set @negQty = 0
set @negInventoryAmount = 0
end
else
begin
if (@negQty * -1) < @posQty
begin
insert into work_invent_trans_aging
values (@negRecid, @posRecid, @itemid, @dataareaid, @negDatestatus, @posDatestatus, @negQty, 'New3', @negInventoryAmount)
set @posQty = @posQty + @negQty
set @posInventoryAmount = @posInventoryAmount + @negInventoryAmount
set @negQty = 0
set @negInventoryAmount = 0
end
else
begin
–Write into result table the consumed positive amount
insert into work_invent_trans_aging
values (@negRecid, @posRecid, @itemid, @dataareaid, @negDatestatus, @posDatestatus, (@posQty * -1), 'New4', (@posInventoryAmount * -1))
set @negQty = @negQty + @posQty
set @negInventoryAmount = @negInventoryAmount + @posInventoryAmount
update @posTable
set posProcessed = 0
where posDatestatus = @posDatestatus
and posRecid = @posRecid
select @posRecid = posRecid, @posDatestatus = posDatestatus, @posQty = posQty, @posInventoryAmount = posInventoryAmount from @posTable p1 where posProcessed 0 order by posDatestatus desc, posRecid desc
end
end
end
end
update @negTable
set negProcessed = 0
where negDatestatus = @negDatestatus
and negRecid = @negRecid
set @negDatestatus = NULL
set @negQty = NULL
set @negRecid = NULL
end
–select * from @posTable t1 order by t1.posDatestatus, posRecid
–select * from @negTable t1 order by t1.negDatestatus, negRecid
–Clear aging variables
set @negDatestatus = NULL
set @negQty = NULL
set @negRecid = NULL
set @negInventoryAmount = NULL
set @posDatestatus = NULL
set @posQty = NULL
set @posRecid = NULL
set @posInventoryAmount = NULL
delete @negTable
delete @posTable
update #tempAgingRecords
set processed = 0
where itemid = @itemid
and dataareaid = @dataareaid
end
END
GO
Please, when you post something that you are trying to explain it to the community, provide samples like in your other posts, for me is very abstract sample about Try and Catch
BEGIN TRY
–Your t-sql code goes here (give a example here)
END TRY
BEGIN CATCH
–Your error handling code goes here (give a example here)
END CATCH
Anyway thank you for the tips…
Knowing that it is there to use, you could always take a look in Books Online or search elsewhere for in depth examples. There are lots of examples and trying them out will help you understand how it works more clearly. This set of tips doesnt go in to depth on any of the items as they each could have an article on their own.
If i am using temporary tables, local and global in some of my store procedures, should i use indexes (clustered & non-clustered) on these tables to get maximum performance, specially when i know that these temporary tables will contain lot of rows ???
Hello Aasim,
Creating an index to be used for once would not provide any improvement because processing consumed to create an index itself would overcome the benifit of its uses. We should create an index on any table (permanent or temporary table) if that is usable in more than one statements.
Regards,
Pinal Dave
Hello Aasim,
Like SQL Genius (Pinal) said, if we use temp tables more than once in stored procedure, then definitely it is suggested to create indexes on temporary tables especially when you are dealing with huge amounts of data.
I have seen significant differences in my procedure performance after I created Indexes on huge temp tables.
~ IM.
I would create an index if a temp table contained a lot of rows and was going to be used to join another table.
Hello Pinal,
Sorry, but I disagree with your statement about there is no sense for creating an index on # table if this index will be used just once. Many times in my practice “creation index on the fly” saved tens of minutes, sometimes hours on data processing. It is all about data amount. Sometimes you can’t avoid of using a # table and that table becomes huge in some cases. When we talking about million records temporary table and we have to join this table with another multimillion table we have to create indexes otherwise we can wait forever till procedure is completed.
When we have deal with VLDB, the creation of index(es) on # table on the fly is definitely solution.
BTW, very nice site, I like it, thank you!
Thanks,
IgorA
Very useful tips…. thanks
HI Pinal i have a question i have a stored procedure which takes 1 hour for execution and how i can check whether it is progressing or not ?
Aasim,
I would profile the procedure with/without indexes, and then decide what is the actual best practice for your case.
A very good the article.
Hi Pinal,
Nice set of tips, especially the one on execute and sp_executesql.
Thank you
Ramdas
Hello!
Interesting that you wrote this article today. Along with my other responsibilities, I am also part of the DBA team and was working on a code review today and recommended the usage of schema qualifiers (dbo.MyStoredProcedure) for the stored procedures. I had logically thought it through and was going to do a little experiment tomorrow to see the performance difference that qualifers provide. I will run the test tomorrow and update if time permits.
Great compilation, by the way. I agree with Jacob – this should be part of every database developer’s/administrator’s checklist.
Have a Great Day!
Use schema name with object name:
I executed the both queries with schema name and without schema name and checked the execution plan of both the queries.I didn’t find any differrence.
Does anyone have solution how to prove this tip?
whenever we execute any SELECT query first database engine checks in master database. if it’s not there in master database it checks in the current session database depends on schema.
Thanks for some great tips that I am sure to use!
Thanks a lot. Very useful tips
Very Good Tips for Writing Stored Procedure.
It help a lot when you are not familiar in writing SP in sql server.
Regarding using point on
Use IF EXISTS (SELECT 1) instead of (SELECT *):
There is no guarantee SELECT 1 will outperform SELECT *
Also the result is a boolean value and it doesn’t matter how many columns are used inside EXISTS
Regarding using point on
Use IF EXISTS (SELECT 1) instead of (SELECT *):
There is no guarantee SELECT 1 will outperform SELECT *
Also the result is a boolean value and it doesn’t matter how many columns are used inside EXISTS
Well, I would think that in the case of EXISTS the subquery is terminated when first matching row is found and only boolean value is returned. This would seem logical.
But since MSDN doesn’t say anything about this I think the safest way would be to use:
EXISTS (SELECT TOP(1) 1 FROM foo WHERE bar = ..)
This is because if subquery isn’t terminated it would do the matching against all the rows in ‘foo’ and return 0..n rows. This means that there would be 0..n unneccessary matching operations and 0..n * column_count data readings.
With TOP(1) you tell that you are only insterested in the first matching row and no subsequent rows are matched. And because you are returning constant value 1 there will be no unnecessary read operation to the table.
Okay. I went ahead and tested this. It seems that there’s no diffence between any of these:
SELECT 1 FROM MyTable WHERE EXISTS (SELECT * FROM MyTable)
SELECT 1 FROM MyTable WHERE EXISTS (SELECT 1 FROM MyTable)
SELECT 1 FROM MyTable WHERE EXISTS (SELECT TOP(1) 1 FROM MyTable)
I’ve heard from others to use EXISTS (SELECT *) because it allows SQL Server to select the best index. Also, the exists clause causes it to select only one row
@rudesyle
INDEX usage would not be based on the *, but on the WHERE clause. Think about it, EXISTS causes a lookup which we are hoping to be an INDEX scan of sorts. The match is based on the WHERE clause where the correlation is defined.
@Madhivann
Technically, SELECT 1 is faster:
Brad Schulz has a nice write-up here:
Personally, i use * because it states explicitly “i don’t want the results”. Anything else might give the developer pause.
Brian,
From link1
However, at runtime the two forms of the query will be identical and will have identical runtimes.
So SELECT 1 is not faster
Aslo from link2
Sure, it will take a couple of extra femtoseconds to compile (compared to the boring SELECT 1),
See the definition of femtoseconds
It is actually very negligible in real time
https://en.wikipedia.org/wiki/Femtosecond
@Madhivanan
Yes, but the expansion itself takes time! :)
When Brad said femtoseconds, he was being facetious.
The idea here is, it does take longer, just not much. As is a very, very, very, very, very, very, tiny bit longer.
Pinal, this is great stuff!
Guys – regarding the “select 1” versus “select *”, I feel you are missing something here.
I have seen notable peformance improvements by using SELECT 1 instead of SELECT *. Looking at the Execution Plan to address to performance, I could see that SELECT * was having to bring back all fields using the clustered index. When SELECT 1 was used instead, a covering index based on the WHERE clause was used by the engine and performance was notably better. As in a query taking 4 secs now takes 0.15 secs.
Also, from a developers point of view, SELECT 1 is preferred because it is symantically stating that the fields are not important to the query.
Thanks Pinal . It’s a great tips.
These tips are very useful an SQL Developer!!!
Thanks Pinal
Beginner like me it’s a great tips.
As Madhivanan points out, there is no benefit in the ‘select 1’ syntax over ‘select *’ if you’re using ‘if exists’ at the same time.
There is no data processed from the query inside the ‘exists’ clause and so it makes no difference what you ‘select’. Books Online’s examples for the ‘exists’ keyword uses the ‘select *’ syntax.
A much more important point to make is not to perform a count and compare it to zero (a lot of people seem to do this) – so:
if (select count(*) from …) > 0
is especially bad, and should be replaced with
if exists (select * from …)
instead.
Great Article
Tips will helpful so much for beginners like me
Thank You
Nice set of tips.
A couple of things that every developer should realize is that before directly jumping to tune your stored procedures, make sure you have checked your table size, schema, index information etc etc. Most of the times, the ’cause’ of slow performing queries is bad design.
Check the Tuning advisor https://docs.microsoft.com/en-us/sql/tools/dta/tutorial-database-engine-tuning-advisor?view=sql-server-2017
Thanks Pinal,
lovely tips… are they only or there exists any more tips?
Thanks,
Nitin Sharma
Best stored procedures optimization tip => do NOT use them!
Do you have any valid reasons?
Hi,
On the part where you’ve suggested not to use the ‘SP_’ prefix. Wouldn’t that be a problem only if you are creating stored procedures using the dbo schema.
Please elaborate the issue.
Regards.
Hello Hamza,
A stored procedure with prefix “sp_” whether in dbo schema or user defined schema, whether fully qualified name or non-qualified name, always first checked in master database. And if your stored procedure is in another database then an extra search would be an overhead every time you call that stored procedure.
Regards,
Pinal Dave
That’s why I say
SQLAuthority rocks!!!