
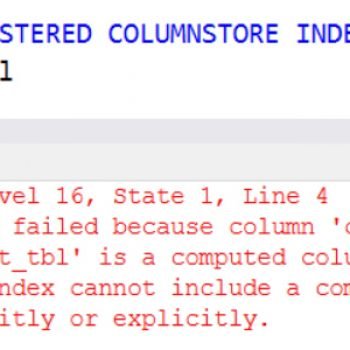
Q. What is Fragmentation? How to detect fragmentation and how to eliminate it?
A. Storing data non-contiguously on disk is known as fragmentation. Before learning to eliminate fragmentation, you should have a clear understanding of the types of fragmentation. We can classify fragmentation into two types:
- Internal Fragmentation: When records are stored non-contiguously inside the page, then it is called internal fragmentation. In other words, internal fragmentation is said to occur if there is unused space between records in a page. This fragmentation occurs through the process of data modifications (INSERT, UPDATE, and DELETE statements) that are made against the table and therefore, to the indexes defined on the table. As these modifications are not equally distributed among the rows of the table and indexes, the fullness of each page can vary over time. This unused space causes poor cache utilization and more I/O, which ultimately leads to poor query performance.
- External Fragmentation: When on disk, the physical storage of pages and extents is not contiguous. When the extents of a table are not physically stored contiguously on disk, switching from one extent to another causes higher disk rotations, and this is called Extent Fragmentation.
Index pages also maintain a logical order of pages inside the extent. Every index page is linked with previous and next page in the logical order of column data. However, because of Page Split, the pages turn into out-of-order pages. An out-of-order page is a page for which the next physical page allocated to the index is not the page pointed to by the next-page pointer in the current leaf page. This is called Logical Fragmentation.
Ideal non-fragmented pages are given below:

Statistics for table scan are as follows:
- Page read requests: 2
- Extent switches: 0
- Disk space used by table: 16 KB
- avg_fragmentation_in_percent: 0
- avg_page_space_used_in_percent: 100
Following are fragmented pages:

In this case, the statistics for table scan are as follows:
- Page read requests: 6
- Extent switches: 5
- Disk space used by table: 48 KB
- avg_fragmentation_in_percent > 80
- avg_page_space_used_in_percent: 33
How to detect Fragmentation: We can get both types of fragmentation using the DMV: sys.dm_db_index_physical_stats. For the screenshot given below, the query is as follows:
SELECT OBJECT_NAME(OBJECT_ID), index_id,index_type_desc,index_level,
avg_fragmentation_in_percent,avg_page_space_used_in_percent,page_count
FROM sys.dm_db_index_physical_stats
(DB_ID(N'AdventureWorksLT'), NULL, NULL, NULL , 'SAMPLED')
ORDER BY avg_fragmentation_in_percent DESC

Along with other information, there are two important columns that for detecting fragmentation, which are as follows:
- avg_fragmentation_in_percent: This is a percentage value that represents external fragmentation. For a clustered table and leaf level of index pages, this is Logical fragmentation, while for heap, this is Extent fragmentation. The lower this value, the better it is. If this value is higher than 10%, some corrective action should be taken.
- avg_page_space_used_in_percent: This is an average percentage use of pages that represents to internal fragmentation. Higher the value, the better it is. If this value is lower than 75%, some corrective action should be taken.
Reducing fragmentation:
- Reducing Fragmentation in a Heap: To reduce the fragmentation of a heap, create a clustered index on the table. Creating the clustered index, rearrange the records in an order, and then place the pages contiguously on disk.
- Reducing Fragmentation in an Index: There are three choices for reducing fragmentation, and we can choose one according to the percentage of fragmentation:
- If avg_fragmentation_in_percent > 5% and < 30%, then use ALTER INDEX REORGANIZE: This statement is replacement for DBCC INDEXDEFRAG to reorder the leaf level pages of the index in a logical order. As this is an online operation, the index is available while the statement is running.
- If avg_fragmentation_in_percent > 30%, then use ALTER INDEX REBUILD: This is replacement for DBCC DBREINDEX to rebuild the index online or offline. In such case, we can also use the drop and re-create index method.
- (Update: Please note this option is strongly NOT recommended)Drop and re-create the clustered index: Re-creating a clustered index redistributes the data and results in full data pages. The level of fullness can be configured by using the FILLFACTOR option in CREATE INDEX.
Reference: Pinal Dave (https://blog.sqlauthority.com)




77 Comments. Leave new
Brilliant! Thank you!
we have one sp.It is taking 7 mins to generate the report.Can u solve this
You are awesome ever
Easy to get the content
Thanks a lot
I am sure you guys can make on a lot better then this, but I wrote a small procedure to schedule the maintenance as explained in this article:
/*Perform a ‘USE ‘ to select the database in which to run the script.*/
— Declare variables
SET NOCOUNT ON
DECLARE @tablename VARCHAR (128)
DECLARE @IxName VARCHAR (255)
DECLARE @Avg_Frag float
DECLARE @Avg_Page float
DECLARE @Action NVARCHAR(10)
DECLARE @Query NVARCHAR(700)
— Declare cursor
DECLARE tables CURSOR FOR
SELECT SO.name, SI.name,avg_fragmentation_in_percent,avg_page_space_used_in_percent,
(CASE WHEN avg_fragmentation_in_percent > 30 OR avg_page_space_used_in_percent 5.0 –Only indexes with fragmentation
AND sys.dm_db_index_physical_stats.record_count > 1000 –Only table with more then 1000 records
AND sys.dm_db_index_physical_stats.index_id > 0
— Open the cursor
OPEN tables
— Loop through all the tables in the database
FETCH NEXT
FROM tables
INTO @tablename,@IxName, @Avg_Frag,@Avg_Page,@Action
WHILE @@FETCH_STATUS = 0
BEGIN
— Do the showcontig of all indexes of the table
set @Query = null
IF @Action = ‘Rebuild’
BEGIN
set @Query = ‘ALTER INDEX ‘ + rtrim(@IxName) + ‘ ON ‘ + rtrim(@tablename) + ‘ REBUILD’
print @Query
EXEC sp_executesql @Query
END
IF @Action = ‘Org’
BEGIN
set @Query = ‘ALTER INDEX ‘ + rtrim(@IxName) + ‘ ON ‘ + rtrim(@tablename) + ‘ REORGANIZE’
print @Query
EXEC sp_executesql @Query
END
FETCH NEXT
FROM tables
INTO @tablename,@IxName, @Avg_Frag,@Avg_Page,@Action
END
— Close and deallocate the cursor
CLOSE tables
DEALLOCATE tables
DECLARE tables CURSOR FOR
SELECT SO.name, SI.name,avg_fragmentation_in_percent,avg_page_space_used_in_percent,
(CASE WHEN avg_fragmentation_in_percent > 30 OR avg_page_space_used_in_percent 5.0 –Only indexes with fragmentation
AND sys.dm_db_index_physical_stats.record_count > 1000 –Only table with more then 1000 records
AND sys.dm_db_index_physical_stats.index_id > 0 , Getting error here , Can you correct and post the updated one
backup started at 2 pm and completed at 6.00pm ,in between this time if any transaction as occured will it be retrieved or lost.
Hi Pinal,
The article is really helpful.
I need your guidance for few things.
I have a SQL database (size is more than 800 GB). The database is a central database, it gathers data from different 200 + source databases (can grow to 1500 databases) through Microsoft sync service.
The sync service runs every hour to sync data from all sources to this central database.
There are also few jobs which run every hour to process data(SP is executed in job).
Now every hour database tables goes under heavy deletes, updates and inserts.
I tried the same query to detect fragmentation on one table, it took more than hour and did not complete i stopped it.
Please guide me how to detect fragmentation in this case ? why the query takes long time ? what can be ways to detect fragmentation and maintain the database ?
do i need to take a downtime (stop every job and service) to execute the script and detect fragmentation ?
You need to figure out the waits which are happening in the SQL Server. Fragmentation removal may not be a solution for you.
Hi sir i have read soo many of your articles but i have some small small doubts in many . I know how to perform fragmentation but i don’t know when to perform fragmentation. What causes us to check for fragmentation.
Dear Pinal,
We have discussed extensively on fragmentation removal in case a clustered index is already present. But reducing the same in a heap is still unanswered (as creation of an index is not recommended by Paul). Kindly suggest for this as well.
Regards,
Mayank
I am trying to use this sys.dm on a SQL2014 database. Do you have any idea why the view doesnt exist? Is there something I need to invoke to cause it to be available? It works in many other installations I have, but I’ve looked and it is not there in this particular instance.
It turned out I was looking at a case sensitive server. I currently manage 200+ SQL instances, and for some reason, this is the only instance with that setting (SAP, I now know is case sensitive by default). It was dumb of me not to realize it. I changed all my scripts to be sure they will work, when/if I ever work on another case sensitive server – DOH!!!
Thank you for getting back to me.
Hi Pinal
I have a table with 6.3 mil rows, a unique clustered index on this table with combination of 4 fields. This index always show 100% avg_fragmentation_in_percent, index level 2, pages =8. I have tried reorganize, rebuild and even tried dropping them and creating again. However, each time I check (even immediately after recreating the indexes) the avg_fragmentation_in_percent shows 100%. I have pasted the create syntax below for your reference.
Can you please suggest if I am missing anything, or any help to resolve this is appreciated.
Thanks
Joy
CREATE UNIQUE CLUSTERED INDEX [CIX_RCP_xxxxxx] ON [dbo].[RCP_xxxxxx]
(
[AwId] ASC,
[KType] ASC,
[SortNumber] ASC,
[LabourHours] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
Hi Pinal,
Do we need to rebuild non-clustered indexes after we rebuilt clustered ones on the same table?
Awesome. Its pretty good and clear… Thanks a lot!
Hi Pinal,
a quick question (I hope): if there is more than one index to rebuilt/reorganize, would you do it to the entire table or just to the single indexes?
Thanks
Single Index.
Hi sir, How to remove Internal Fragmentation ?
The use of a dynamic partitioning scheme and best-fit block search are the solutions that can reduce internal fragmentation.