

When you test an application that implements billing features, meaningful test data is extremely important. This article teaches how to quickly obtain and populate your database with live currency exchange rates in a few simple steps. Let us learn about Generate Live Currency Exchange Rates.
SQL SERVER – Beautify SQL Code with dbForge SQL Complete
Often when you write a large piece of SQL code, it eventually becomes a bit disorganized, or when a big team of developers is working on one project, the code differs between individual developers, the code formatting throughout the project gets inconsistent and hard to read. Let us learn about how to Beautify SQL Code with dbForge SQL Complete.

dbForge Studio for SQL Server – Ultimate SQL Server Manager Tool from Devart
dbForge Studio for SQL Server is a powerful IDE for managing, administrating, configuring, developing various components of SQL Server. The tool incorporates various graphical utilities and script editors allowing developers and administrators to access and manage SQL Server. You can download the latest version of dbForge Studio for SQL Server from the Devart website.

SQL SERVER – How to Automatically Generate SQL Server Documentation ?
A complete and precise documentation serves a good basis for developers and DBAs during their onboarding to get a general picture of the database they start working with. Creating such a documentation manually takes a lot of time and effort. So you seat for hours and hours digging through the database structure figuring out its functionality, data types stored therein, building relationship diagrams, etc. Moreover, every time changes are introduced to the database, you have to get back to it update the documentation by hand. This definitely feels like a burden and you keep delaying it until the last minute.
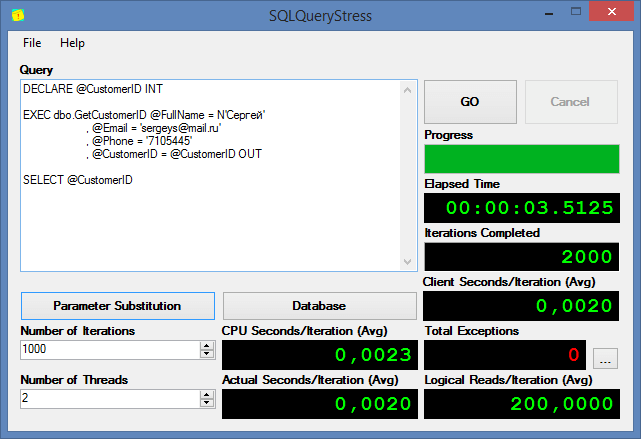
SQL SERVER – Testing Database Performance with tSQLt and SQLQueryStress
I guess, it is no secret that testing plays a critical part in development of any software product. The more rigorous testing is, the better the final product will be. In this blog post we will be Testing Database Performance with tSQLt and SQLQueryStress.

Creating and Running an SQL Server Unit Test – Best Ways to Test SQL Queries
I hope it is no secret that testing of written code is as important as writing the code itself, and sometimes even more important. Writing unit test for C#/Java/…code coverage is the responsibility of each software developer.
However, there is not always an opportunity to use autotests. For example, until recently, there were no good computer-aided testing systems for SQL Server, and many people had to create self-made products that were expensive to support and develop. To tell the truth, I was doing that too.

SQL SERVER – Summer Sale and Monowheel Raffle
My good old friends from Devart keep exciting me with great news. As it became a tradition, the company treats its customers with “tasty” discounts on all its product range. But there’s more – each customer gets a chance to win a monowheel in the end of the summer sale. See details below.