
 [Note from Pinal]: In this episode of the Notes from the Field series database expert Kathi Kellenberger explains about indexes and its impact. We often believe that indexes will improve the performance of the query, but it is not true always. There are cases when indexes can reduce the performance as well. Read the experience of Kathi in her own words.
[Note from Pinal]: In this episode of the Notes from the Field series database expert Kathi Kellenberger explains about indexes and its impact. We often believe that indexes will improve the performance of the query, but it is not true always. There are cases when indexes can reduce the performance as well. Read the experience of Kathi in her own words.
Having the correct indexes in place can improve the performance of your queries immensely. Knowing just what the correct indexes are, however, is not an easy task. SQL Server provides tools to help you create indexes based on a specific query or the workload that has run since the last restart of the instance. While these are handy tools, you must take the guidance they give with the time-honored grain of salt.
Having done my share of index tuning over the past few years, I have seen the consequences of blindly creating indexes based on the suggestions of the Database Engine Tuning Advisor, the missing index DMV, or the missing index recommendation found in the execution plan. It’s easy to copy a slowly running query into the Query window of SSMS and view the execution plan only to find that an index can be created to drastically improve the query performance. The problem is that this recommendation does not consider indexes that are already in place. By creating every index that these tools suggest, you will end up with too many indexes and many that overlap. At first you may not think this is a problem: more is better, right?
Having too many nonclustered indexes can cause numerous problems. First, unneeded indexes take up space. This impacts storage costs, backup and recovery times, and index maintenance times. Indexes must be kept up to date whenever data changes. The performance of inserts, updates, and deletes is impacted by nonclustered indexes. Have you ever heard of a SELECT query that runs more slowly because there are too many indexes on a table? I have seen it happen. When the optimizer comes up with a plan for a query, it must consider the available indexes, three types of joining, order of joins, etc. The number of plan choices increases exponentially. The optimizer won’t take long to come up with a plan, however, and will sometimes stop with a “good enough plan”. It’s possible that the optimizer didn’t have enough time to figure out the best index because there were too many to consider.
To avoid creating unnecessary indexes, always take a look at the existing indexes on the table when you think you should add a new one. Instead of creating a brand new index, maybe you can just add a key or included columns to an existing index. Following this practice will help keep the number of indexes from spiraling out of control. Another thing to watch out for is the cluster key. The cluster key is included in every nonclustered index. It’s there to locate rows in the clustered index, but you won’t see it in the nonclustered index definition. The index tools will often tell you to add the cluster key as included column, but that is not necessary.
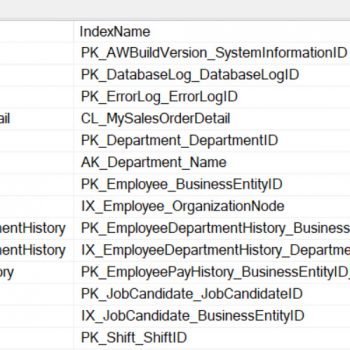
By following all of the index recommendations from the tools without considering other indexes, you will end up with tables that resemble the following:
CREATE TABLE TestIndexes(Col1 INT, col2 VARCHAR(10), Col3 DATE, Col4 BIT);
CREATE INDEX ix_TestIndexes_Col1 ON dbo.TestIndexes (col1);
CREATE INDEX ix_TestIndexes_Col1_Col2 ON dbo.TestIndexes (col1, col2);
CREATE INDEX ix_TestIndexes_Col1_Col2_Col3 ON dbo.TestIndexes (col1, col2, Col3);
CREATE INDEX ix_TestIndexes_Col2 ON dbo.TestIndexes (col2);
CREATE INDEX ix_TestIndexes_Col1_includes1 ON dbo.TestIndexes (col1) INCLUDE(Col4);
CREATE INDEX ix_TestIndexes_Col1_includes2 ON dbo.TestIndexes (col1) INCLUDE(Col2);
You may think that this is a contrived example, but I see this pattern all the time. How do you find the overlapping indexes that need to be cleaned up? There are many scripts available, but here is a simple script that just looks at the first two index keys for duplicates:
WITH IndexColumns AS (
SELECT '[' + s.Name + '].[' + T.Name + ']' AS TableName,
i.name AS IndexName, C.name AS ColumnName, i.index_id,ic.index_column_id,
COUNT(*) OVER(PARTITION BY t.OBJECT_ID, i.index_id) AS ColCount
FROM sys.schemas AS s
JOIN sys.tables AS t ON t.schema_id = s.schema_id
JOIN sys.indexes AS i ON I.OBJECT_ID = T.OBJECT_ID
JOIN sys.index_columns AS IC ON IC.OBJECT_ID = I.OBJECT_ID
AND IC.index_id = I.index_id
JOIN sys.columns AS C ON C.OBJECT_ID = IC.OBJECT_ID
AND C.column_id = IC.column_id
WHERE IC.is_included_column = 0
)
SELECT DISTINCT a.TableName, a.IndexName AS Index1, b.IndexName AS Index2
FROM IndexColumns AS a
JOIN IndexColumns AS b ON b.TableName = a.TableName
AND b.IndexName <> a.IndexName
AND b.index_column_id = a.index_column_id
AND b.ColumnName = a.ColumnName
AND a.index_column_id < 3
AND a.index_id < b.index_id
AND a.ColCount <= B.ColCount
ORDER BY a.TableName, a.IndexName;

Once you find indexes that are subsets or even exact duplicates of other indexes, you should manually review each match and figure out what can be deleted or consolidated. Just be sure to test your changes before implementing them in production. After reviewing the information, I came up with the following changes:
DROP INDEX ix_TestIndexes_Col1 ON TestIndexes;
DROP INDEX ix_TestIndexes_Col1_Col2 ON TestIndexes;
DROP INDEX ix_TestIndexes_Col1_Col2_Col3 ON TestIndexes;
DROP INDEX ix_TestIndexes_Col1_includes1 ON TestIndexes;
DROP INDEX ix_TestIndexes_Col1_includes2 ON TestIndexes;
CREATE INDEX ix_TestIndexes_Col1_Col2_Col3_includes ON TestIndexes
(Col1, Col2, Col3) INCLUDE (Col4);
Now there are two indexes, none of them overlap, and I haven’t lost anything that was in place before.
I always say that index tuning is both a science and an art. Now when you use the science of missing index information you will know how to apply the art of avoiding duplicates.
If you want to get started with BIML with the help of experts, read more over at Fix Your SQL Server.
Reference: Pinal Dave (https://blog.sqlauthority.com)




4 Comments. Leave new
I’m very surprised about this, is this valid for every version of sql server ? Indexes have a key order it matters when it comes to removing index scan for index seek doesn’t it ?
WHERE clause should be written on that sequence. Though Clo1 = ? and Col3 = ? will go for Index scan.
How can i prevent such similar/duplicated indexes from being created ?
well, not an easy one. you need to check before creating it.