
Filtered Index is a new feature in SQL SERVER. Filtered Index is used to index a portion of rows in a table that means it applies a filter on INDEX which improves query performance, reduces index maintenance costs, and reduce index storage costs compared with full-table indexes.
When we see an Index created with somewhere clause then that is actually a FILTERED.
For Example,
If we want to get the Employees whose Title is “Marketing Manager”, for that let’s create an INDEX on EmployeeID whose Title is “Marketing Manager” and then write the SQL Statement to retrieve Employees who are “Marketing Manager”.
CREATE NONCLUSTERED INDEX NCI_Department ON HumanResources.Employee(EmployeeID) WHERE Title= 'Marketing Manager'
Points to remember when creating a Filtered Ix:
– They can be created only as Nonclustered Index
– They can be used on Views only if they are persisted views.
– They cannot be created on full-text Indexes.
Let us write a simple SELECT statement on the table where we created a Filtered Ix.
SELECT he.EmployeeID,he.LoginID,he.Title FROM HumanResources.Employee he WHERE he.Title = 'Marketing Manager'

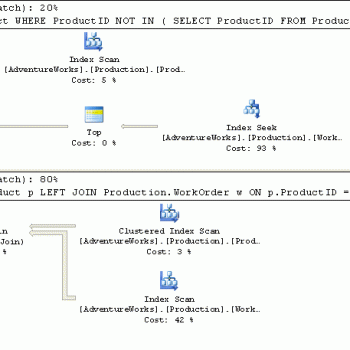
Now we will see the Execution Plan and compare the performance before and after the Filtered Index was created on Employee table.
As we can see, in the first case the index scan in 100% done on the Clustered Index taking 24% of total cost of execution. Once the Filtered index was created on Employee table, the Index scan is 50% on Clustered Index and 50% on Nonclustered Index which retrieves the data faster taking 20% of total cost of execution compared to 24% on the table with no index.

If we have a table with thousands of records and we are only concern with very few rows in our query we should use Filtered Ix.
Conclusion:
A Filtered Index is an optimized non clustered Index which is one of the great performance improvements in SQL SERVER reducing the Index storage cost and reduces maintenance cost.
Reference : Pinal Dave (https://blog.sqlauthority.com)



31 Comments. Leave new
hi,
i am new to sql server. i need some best coding examples for practice. Also need your suggestions for become good in sql server.
waiting for your reply.
[email removed]
One of the problem i faced by applying Filtered Indexes, when I create a agent job that executed TSQL Script (update etc), job fails to run and could not update the table. When I removed the F-Index, script worked perfectly fine.
Amy advice.
Thanks
Can you create columnstore filtered index?
No. https://docs.microsoft.com/en-us/sql/t-sql/statements/create-columnstore-index-transact-sql?view=sql-server-2017
Rebuild is required for Filtered Non-Clustered Indexes? .I’ve table where index created for a column with filter index as “Not null”.
Now the table records grown up to 4 million out of which only 50k contains value rest all has null values.
Rebuiding this index takes more than 2 hours.so Should I rebuild or just update statistics when the data grows.
Hello. I have a question in regards to this issue. Can I create an index where the filter has references to another table. Let us have to tables: A and B, I want table B to have and index only on rows that are related to table A with some values in one of A´s columns.
Table A:
Id Value
1 A
2 B
3 A
Table B:
Id AsId Value
1 1 R
2 1 T
3 1 P
4 2 A
5 3 P
6 3 Q
I would write my index as WHERE EXISTS(SELECT 1 FROM A AS A WHERE A.Id = AsId AND A.Value = ‘B’)
and have my index only contain a single row in the example.
Is that even possible in your knowledge ?
Thanks in advance.
Regards.
Ariel.
In your case, out of 4 million rows only 50k rows has value that means more than 39M rows are NULL; therefore this col should be be changed to SPARSE NULL. This will save disk spare as well as it will improve performance.