
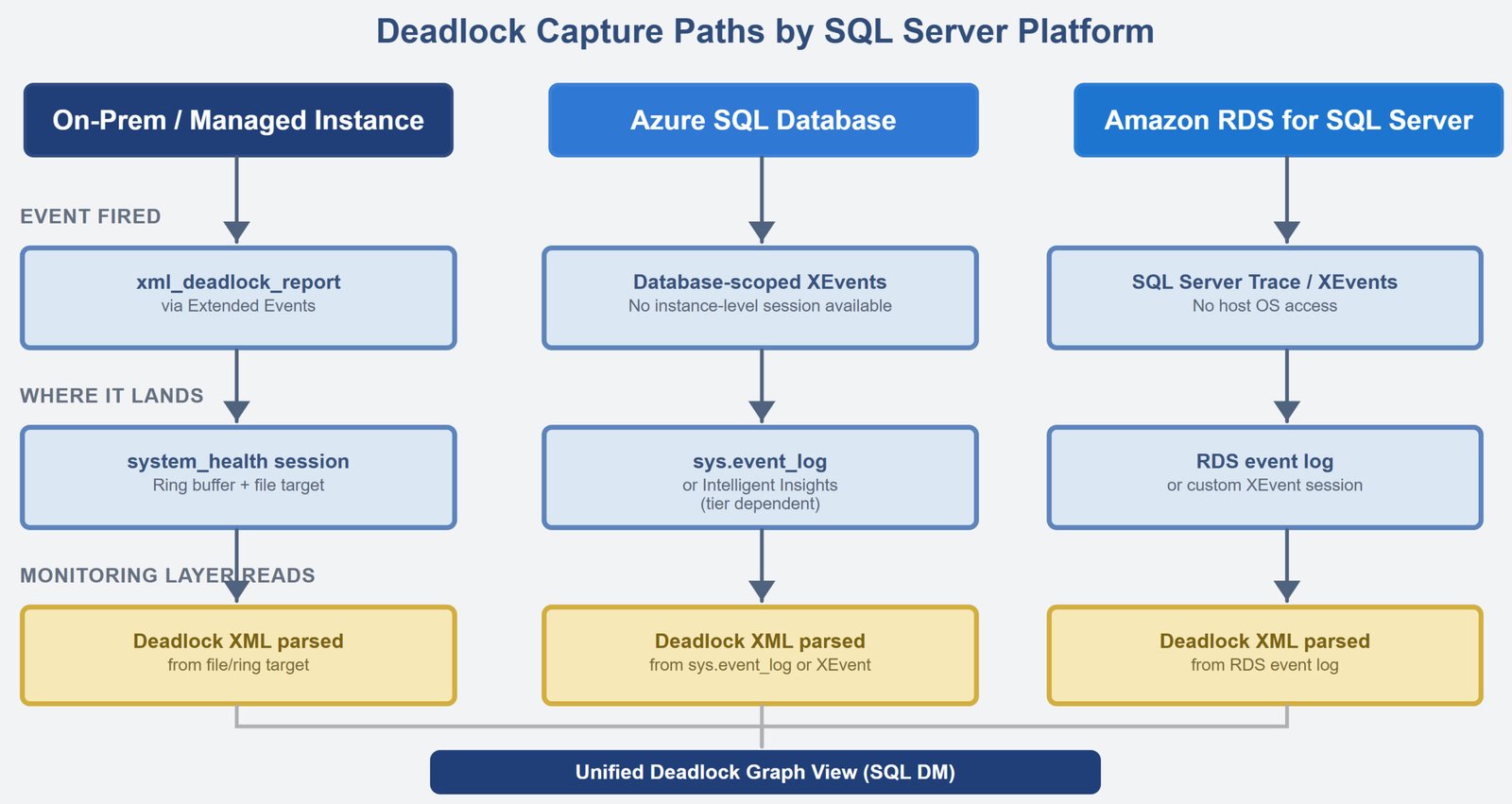
Let us talk about SQL Server Monitoring Across Cloud, Hybrid, and On-Prem. This is not a tooling problem.
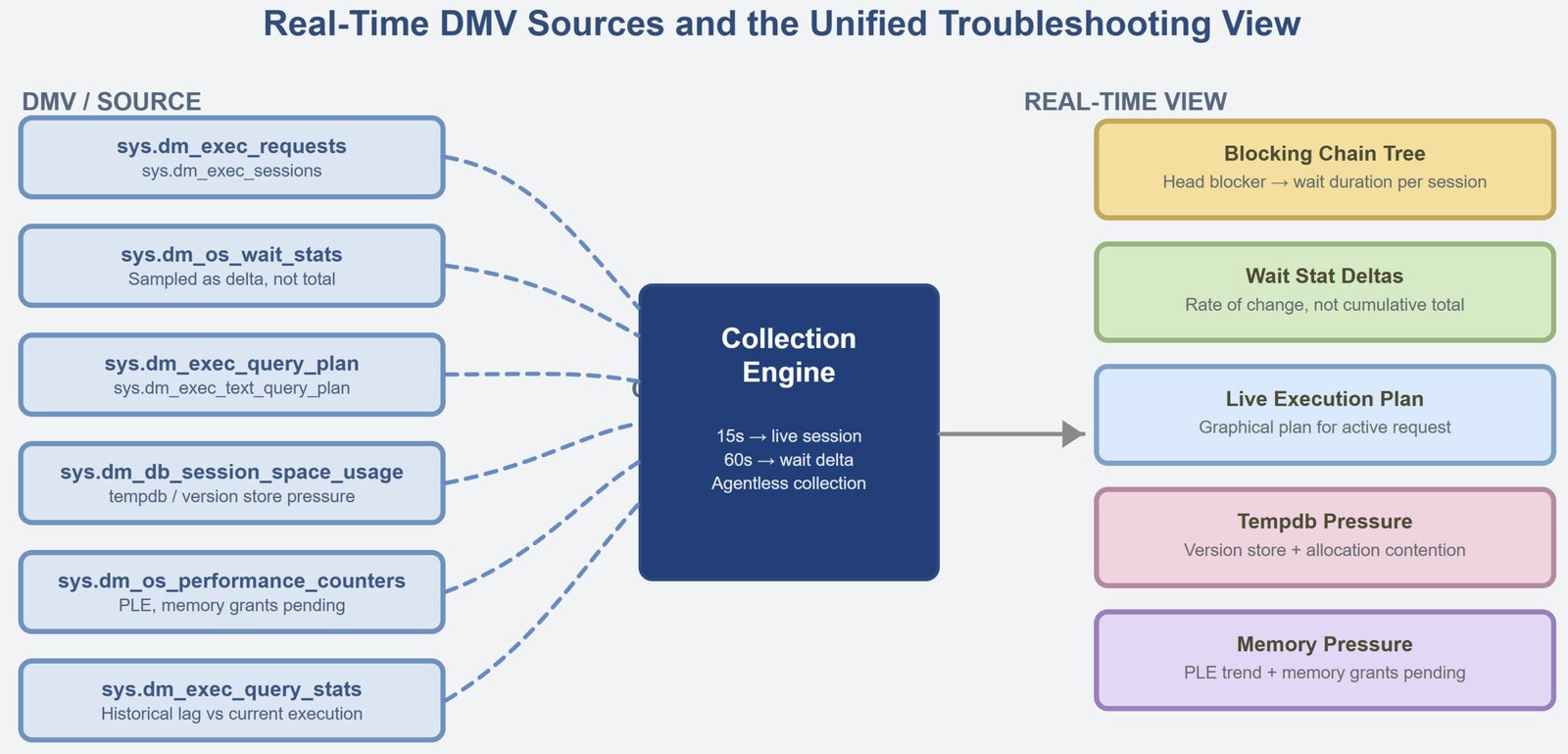
Real-Time Performance Views That Make Troubleshooting Easier
Let us talk about Real-Time Performance Views That Make Troubleshooting Easier. And it is more common than it should be.

Deeper Diagnostics and Actionable Dashboards
That is a harder problem than it looks, and most monitoring tools do not solve it. Let us talk about Deeper Diagnostics and Actionable Dashboards.
Local AI Models for SQL Server – A Complete Guide
Let us learn about Local AI Models for SQL Server – A Complete Guide. What if you could bring the power of AI into SQL Server?

Automating SQL Server Deployments Across Multiple Databases Using Python
Let us learn about Automating SQL Server Deployments Across Multiple Databases Using Python. We have complete script in this blog.

SQL Server Performance Tuning in the Age of AI: An Expert’s Tale
My job? To figure out what went wrong and fix it. Let us talk about SQL Server Performance Tuning in the Age of AI.

A Walkthrough – DATETRUNC Function in SQL Server
One such tool is the DATETRUNC function, introduced in SQL Server 2022. Let’s take a journey to understand how this function can simplify date handling.