
 I wrote the first part of FAQ in here. This is not a typical blog post but more of a process oriented topic when working with ColumnStore Indexes. With the advancements done in SQL Server 2016, I know that this is going to be even more critical to understand some of the nuances of working with ColumnStore indexes inside SQL Server. So what will be target in this post? Here are few questions I asked and I got back in return which form the flow for this post.
I wrote the first part of FAQ in here. This is not a typical blog post but more of a process oriented topic when working with ColumnStore Indexes. With the advancements done in SQL Server 2016, I know that this is going to be even more critical to understand some of the nuances of working with ColumnStore indexes inside SQL Server. So what will be target in this post? Here are few questions I asked and I got back in return which form the flow for this post.
ColumnStore index resulted in a performance regression
On first thought when I heard this from one of the tester, I was baffled to see this was the case. How can this happen. I went the route of asking some fundamental questions to get to the root cause. Here are those for a quick reference and the reason for it:
- Did the optimizer use the ColumnStore index in the first place?
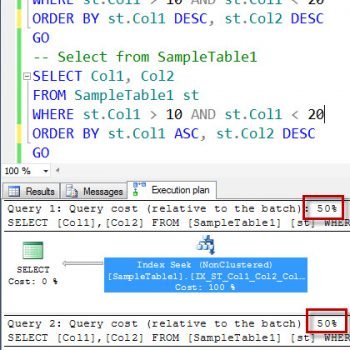
A user can determine whether a ColumnStore index was used in the query plan by looking at the Storage property in SHOWPLAN. Read about batch mode and row mode here.
- Did the query start to execute using the columnstore index with batch processing and then fall back to row-based processing?
A user can determine that the query started to execute in batch mode then fell back to row mode by looking at EstimatedExecutionMode and ActualExecutionMode in Showplan. In most cases, even in row mode the columnstore index will provide better performance than the rowstore. If performance regression due to the columnstore is suspected, a query hint to force use of a different index can be used to prevent the query optimizer from selecting the columnstore. We discussed about some of the query hints that can be used in the previous post.
- Did you insert a FORCE ORDER hint on a join?
If a FORCE ORDER hint is used, optimizer will obey the FORCE ORDER hint. If the optimizer would have used the starjoin optimization and created bitmaps, the loss of the starjoin optimization bitmaps could cause performance to be worse than without the FORCE ORDER hint.
Question: In queries processed in row mode, some filters are evaluated in the storage engine. Can the columnstore do that too for optimization reasons?
Yes, very much. Some filters that are pushed down into the storage engine are:
- comparisons <column, comparison, constant or parameter>
- IN lists <constant1 or parameter1, constant2 or parameter2 … constantN or parameterN>
- IS (NOT) NULL
- BETWEEN
- filters on strings are NOT pushed down
Question: In queries processed in row mode, partitions can (sometimes) be eliminated from the scan. Can the columnstore do that too?
Yes, and no. Partition elimination per se does not occur, however segments (actually row groups – i.e. the corresponding segments for each column) can be eliminated from the scan. Each nonempty partition has one or more segments for each column. Eliminating each segment in a partition is equivalent to partition elimination. Eliminating a subset of segments in a partition for which some values in the partition qualify can be better than partition elimination (because that partition would not be eliminated). Each segment has metadata that includes the min and max values in the segment. Similar min/max metadata associated with bitmaps and filters can be used to determine that none of the values in a segment will qualify without scanning the segment. If a segment is eliminated from the scan, the other segments in the same rowgroup are also eliminated. Column_store_segment_eliminate extended event can be used to see if segments are being eliminated.
Question: Does partitioning work the same way for the columnstore index as for row store indexes?
Mostly, yes. A nonclustered columnstore index can be built on a partitioned table. An empty partition can be split. Two empty partitions can be merged. An empty partition can be merged with a nonempty partition. A partition can be switched between partitioned tables if both tables have a columnstore index and all the other requirements for switching partitions are met. There are some restrictions associated with columnstore indexes:
- If a table has a columnstore indexes, two non-empty partitions cannot be merged
- A nonclustered columnstore index must always be partition-aligned with the base table. As a corollary, the partition function used to partition the nonclustered columnstore index and the base table must be identical, not just equivalent. The reason for this requirement is that otherwise the partition function on the base table could be changed, resulting in non-alignment.
As I conclude for this post, I will try to create supporting posts with scripts to show how the above restrictions apply and how one can figure these when they are implementing ColumnStore Indexes in future posts. Out of curiosity, I would like to know how many of you literally use the ColumnStore Indexes in your environments? What has been your experience using the same?
Reference: Pinal Dave (https://blog.sqlauthority.com)




2 Comments. Leave new
Hello Pinal, We use columnstore index on nonclustered index in our 2012 server. We realized we need to delete some data after creating the index. Is there a way to do this without dropping and rebuilding the index? Since the columnstore index is not updatable in 2012, it is not letting us delete records that we need to. Appreciate your answer. Thanks,
Hi Pinal, I’m working with a vendor developed data warehouse which recently upgraded to SQL 2016 and converted fact tables to use clustered columnstore indexes. Mostly great. However, strangely we’ve found that queries which use the APPLY operator have severely degraded performance. A simple example (not the best use, but still…) would be a query that uses something like the following:
SELECT
…FIELDLIST…
,CASE WHEN CriteriaExample.[KEYFIELD] IS NOT NULL THEN 1 ELSE 0 END
FROM FactTable1
OUTER APPLY (SELECT TOP 1 [KEYFIELD] FROM [FactTable2] FT2
INNER JOIN [DimTable] DT on FT2.[DimKey] = DT.[DimKey] and DT.[FieldValue] = ‘Something’
WHERE [FactTable2.KEYFIELD] = [FactTable1.KEYFIELD]) as CriteriaExample